with assistance from David Kim
Related Categories: Social Networking Systems | Tools for Analyzing Social Networks| Online Knowledge Bases | Text Visualization
Summary:
In 2007, WorldCat, the union catalog of some 71,000 libraries that participate in the Online Computer Library Center (OCLC), implemented WorldCat Identities, which provides a summary page for every name in WorldCat. WorldCat currently includes over 30 million names of authors, filmmakers, fictional characters, actors, and other subjects of published works. The project team, led by Thomas Hickey, included Ralph LeVan, Tom Dehn, and Jenny Toves. It is currently in its Beta stage.
Description:
WorldCat Identities is a search engine built into WorldCat that is focused on individuals both fictional and real. WorldCat itself is a network of libraries in 112 countries worldwide that allows users to locate content pertaining to a particular “Identity” in a succinct one-page layout. “Identities” is the word used by WorldCat to refer to a wide range of figures from writers, journalists, fictional characters, actors, interviewees, directors, producers, etc. These searches result in what the WorldCat blog refers to as the “bibliographic footprint”[i] of these “Identities,” which are comprised of information pulled from bibliographic records in WorldCat. This information varies depending on the type of identity (e.g. publication history for authors, appearances in texts for characters, references and citations in academic criticism).
To start, the opening page of WorldCat Identities presents users with a sparse layout that includes a prominent search bar above a tag cloud of the Top 100 Identities (last name only).
Entering a name, for example Toni Morrison, into the search bar will lead to a search results page with several distinguishing features. The left-hand side of the screen displays the results (last name. first name), with each result further identified with an icon, explained by the “Results Key” box on the right-hand side of the screen. These icons, according to the key, denote whether an identity is “A Personal Identity,” “A Personal Identity from a controlled vocabulary,” “A Corporate Identity,” and “A Corporate Identity from a controlled vocabulary.” In addition, the key notifies us that “Text Size indicates relative popularity of Identity” and parentheses indicate “the Subject Heading associated with that Identity.”
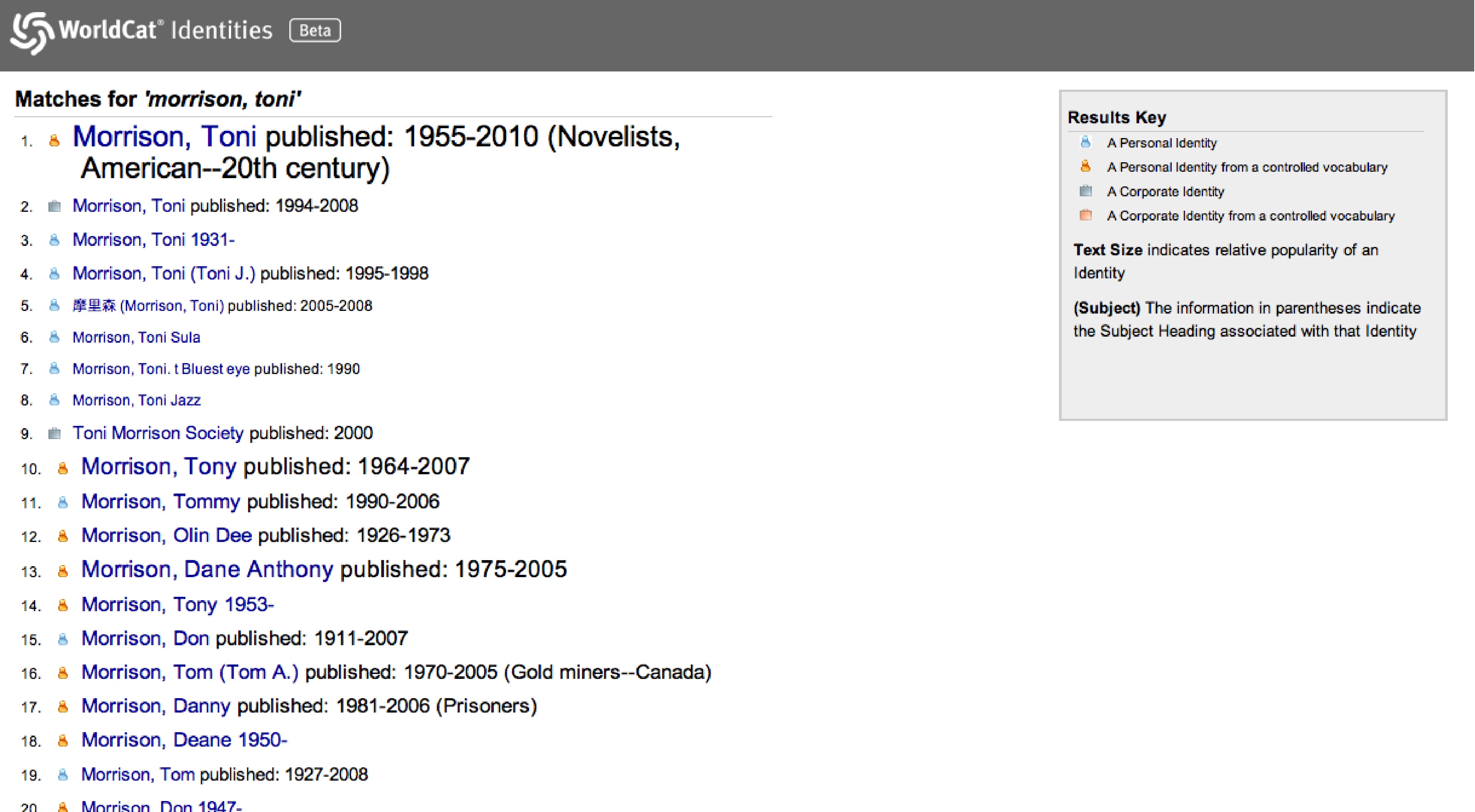
The top-most result, which is also the largest and boldest font-wise, is the “Personal Identity from a controlled vocabulary.” The various other “Personal Identity” pages may or not refer to the same person as the top identity. If they do, they may be specific to a particular publication or time frame, or be the result of some variant or typo from its initial entry at a remote location. “Corporate Identities” refer to the Identity as the subject of books (biographies, etc.), societies (Toni Morrison Society, Jane Austen Society, etc.), professional organizations, publishers, or studios.
Clicking on the topmost Identity leads the user to the main Identity page with the richest and most standardized information of the pages. Each identity page has the following components:
- An Overview
- Publication Timeline
- Works About
- Work By
- Audience
- Related Names
- Useful Links
- Associated Subjects
On Toni Morrison’s main Identity page, the user will encounter the general labels and statistics that WorldCat has assigned her on the main left-hand side of the page, while a smaller side-bar has images of her book covers, along with Alternative Names (birth names, pen names, names in different languages, etc.) and texts by and about her in different languages with links to the WorldCat holdings for those texts. (One comment: under “Languages,” there is one category for “No Linguistic Content” which leads users to listings for audiobooks, images, and videos. For scholars of the digital, this distinction is not only problematic but also incorrect. It is not made in RoSE, where texts in different media are treated the same.)
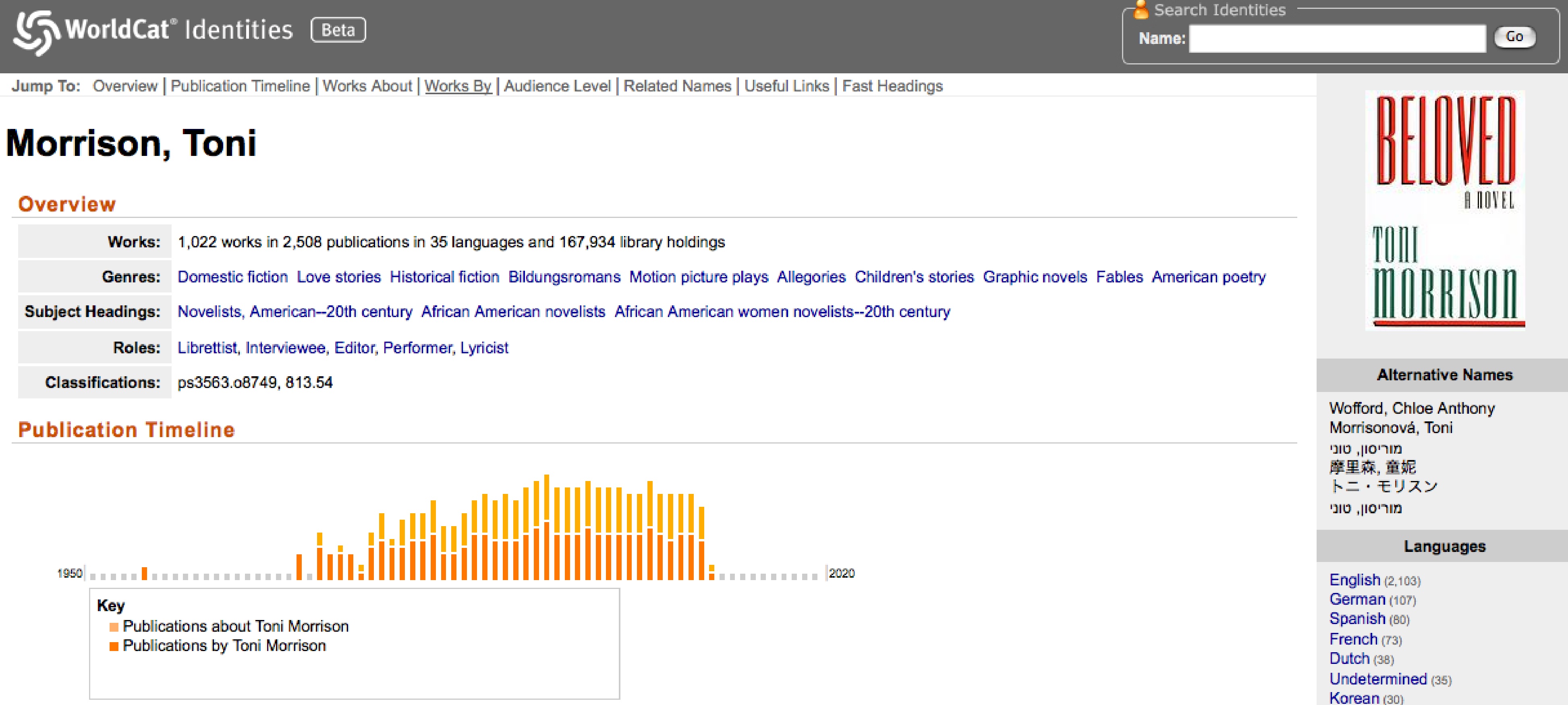
The “Overview” section of an author’s Identity page identifies the number of original “Works” published, in how many different publications, in how many languages, and in how many libraries. The “Genre” subsection provides links to generic labels that most likely do not pertain to specific authors. For example, Toni Morrison’s genres include “Domestic Fiction,” “Love Stories,” “Historical fictions,” and others which are incredibly broad and can lead to a mass of completely unrelated texts. The “Subject Headings” subsection is slightly more specific and applies to Toni Morrison as a person who is identified as being primarily a 20th century African American woman novelist. Her additional “Roles” include such titles as “Librettist,” “Interviewee,” “Editor,” “Performer,” and “Lyricist.” These serve to identify the Identity as an individual along with that individual’s professional roles and catalogued achievements.
The “Publication Timeline,” which immediately follows the “Overview” section, presents a clean horizontal visualization that depicts the Identity’s publications, and publications about that Identity in linear time. Each bar, depending on its respective height, represents the number of publications put out that year. Hovering over a bar will reveal the exact number of publications, though clicking on the bar will take users to a WorldCat search results that can sometimes be buggy. For the most part, though, the search results that come from this timeline will be most relevant for scholarly research, since theses, dissertations, and articles, in addition to essay collections and critical works will turn up alongside the primary works. This diversity of relevant material is not as exhaustive in the following “Works About” section or the “Useful Links” section.
The “Most Widely Held Works About” section is limited to five of the most popular library holdings of published books and collections about that particular identity. The list itself shows only titles, author(s), and type of text. Clicking on the “more” link will lead to an additional 15 titles and authors. Only 20 texts are suggested total.
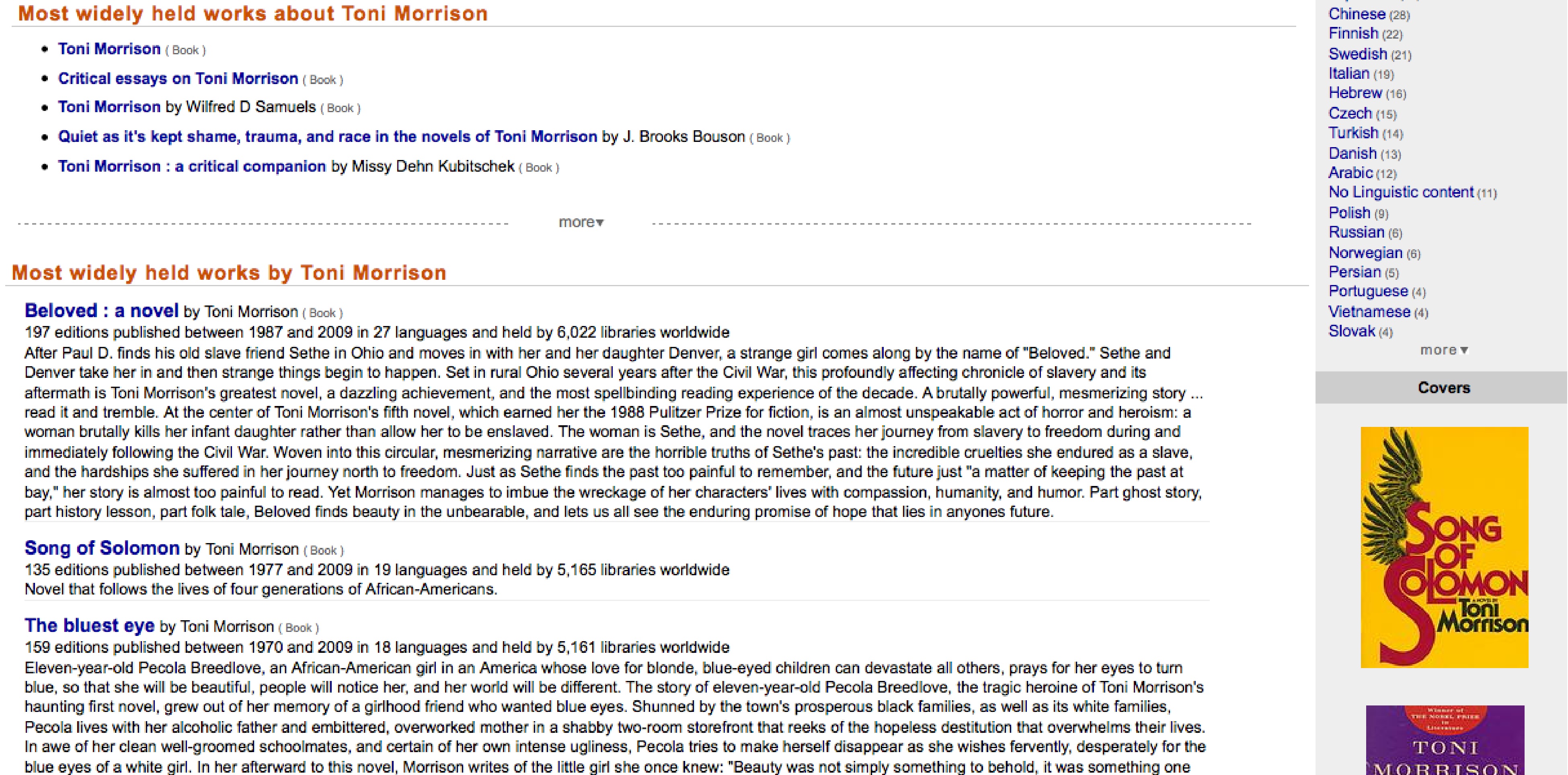
The “Most Widely Held Works By” section lists the top ten most popular library holdings of texts by that Identity. Each listing has a title and format of the text, followed by the number of editions published and during which years, the number of languages the text is available in, and the number of libraries worldwide that carry that text. That one line of dense information is followed by a short abstract. Clicking on the “more” link will reveal an additional 10 texts. This section and the one that precede it are highly limited in that they only list 20 texts for any given Identity regardless of how prolific a writer or filmmaker is.
Following the “Works By” section is a short one called “Audience Level” that is represented in a single-bar chart and in a numeric representation that depict the reading level of the intended audience for the works by this particular author, with 0 being a children’s book (school library), and 1 being a specialist text (American Research Libraries). The “Audience Level”[ii] is the product of the “Audience Level filter” protype which culls information from the standardized WorldCat databases. The text beneath the bar suggest that numeric values are assigned to an author’s most simple text and then his or her most difficult text and these are then averaged to produce the visualized result.

The “Related Names” section provides users with additional authors and Identities who are related to the main Identity based on various professional roles: similar content, themes, and subject type (Alice Walker, Zora Neale Hurston, or Maxine Hong Kingston for Toni Morrison); subjects of their work (William Faulkner appears in Morrison’s dissertation); illustrators (Pascal Lemaitre), narrators, etc.

Clicking on the “+” symbol besides the suggested name leads to a search results page with library holdings that connect the main Identity with the related Identities. In the following example are theses/dissertations, books, films, etc. that connect Toni Morrison and Alice Walker. Clicking on the actual name will lead to that individual’s own WorldCat Identity page.
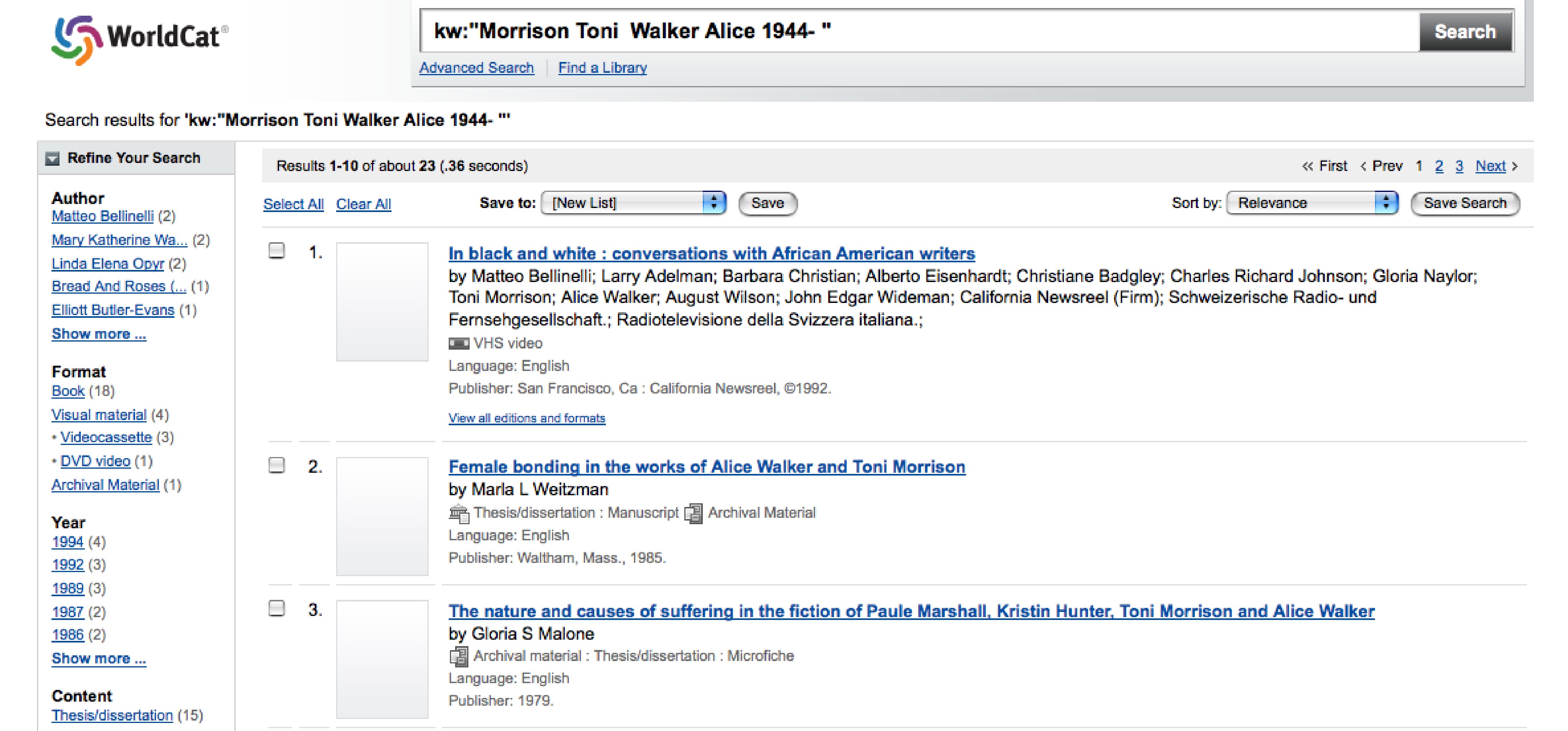
Beneath that section are “Useful Links,” which provide links to external sources like the Library of Congress Authority File or Wikipedia.
The final, and possibly most prominent, section of an Identity page is the “Associated Subjects” tag cloud. This tag cloud is a generic conglomeration of labels that can be applied to a particular individual or his or her work from within the WorldCat controlled vocabulary. The larger tags are the most popular terms associated with the Identity, and the smaller ones less so. Clicking on any of these tags, however, does not necessarily lead to results that are relevant to this particular person or subject as the terms are so broad.
Research Context:
WorldCat Identities aggregates information about various types of individuals (e.g. authors, produces, directors, actors, characters, etc.) and texts from the massive WorldCat database and organizes that information using library cataloging standards and bibliometric methods using different visualization types. The diverse types of individuals and information represented and the attempts to organize and visualize connections between these distinct nodes are relevant in relation to the goals of RoSE as a dynamic social network for research. The system’s accumulation of information for a larger database is relevant to future concerns of document database integration, if RoSE goes in that direction. Additionally, since WorldCat itself is a communally constructed database maintained by all of the participating libraries, it can serve as a helpful model for RoSE as a system that is based around a community of researchers who contribute to and are invested in the growth of the system.
Technical Analysis:
WorldCat Identities uses its own opensource API, comprised of xISBN, sISSN, or xOCLCnum APIs. It allows for data mining of the WorldCat database for information including ISBNs, library locations and holdings, and metadata. Protocols are REST, OpenURL, and unAPI. Data Formats include XML, XHTML, JSON, Python, and Ruby. This API is freely available to those working for “qualifying institutions” for non-commercial use. Such institutions are OCLC member libraries and share information with WorldCat.[iii] The site currently supports Firefox, Safari, and Internet Explorer.
Evaluation of Opportunities and Limitations for Transliteracies:
Perhaps one of the most visible concerns regarding WorldCat Identities is the representation of information, especially regarding people, which is one-dimensional and results in a flat conception of identity that is focused entirely around an individual’s professional output. This echoes the concerns of Mark Seltzer, cited in a previous research report on Freebase, who calls this phenomenon a “statistical person.” In addition, the user/researcher in this process is invisible and plays no role in developing the “Identity” or contributing to the system through the user interface. This treatment of information and identities is constrained by the structures of the library catalog that reduces information into general terms for the sake of the controlled vocabulary, which eases the processes of cataloging and recall, something that RoSE is less interested in. However, this may prove more fruitful in allowing for more rich and vigorous engagements between users, identities, and documents.
In terms of content and metadata, because the content and bibliographic data of WorldCat Identities are pulled from the larger WorldCat database and is not user-generated, the results and the amount of information that can go into enriching an identity are rather limited. This is where RoSE shows much more potential in terms of fleshing out details and connections between people and documents using a folksonomic approach to tagging and labeling content (much like Wikipedia in comparison to Encyclopedia Britannica), if RoSE continues to privilege user-generated data.
At the same time, because WorldCat employs a controlled vocabulary based on library cataloging standards, it allows for more standardization of content within their system. This would be useful for RoSE to reduce redundancies that are a result of variations, misspellings, etc. and instead produce more consistent individual author/user profile pages. As can be seen from any results page after running a search, there are still variations within WorldCat Identities, but the richest results, which appear higher, larger, and bolder, are those individual identities compiled using a controlled vocabulary. RoSE could use WorldCat Identities as a model to standardize names and types of relevant information for profile pages, but currently that could only be done manually with cross-referencing done by those who are entering data, since WorldCat only allows for employees of networked libraries to make use of its API.
In addition, WorldCat’s use of bibliometric tools to trace relations amongst citations and references in journals, articles, books, etc. can be useful for RoSE’s future development, especially in regards to automating relationships occurring between texts and authors. Through WorldCat Identities, bibliometric tools (like citation and content analysis) are used in a somewhat limited capacity–only a maximum of 20 texts for “works about” an author and “works by” an author (and primarily books and films) are listed after clicking on the “more” link, with no option to find more sources through that specific page. Though these works are linked to the actual library holding, which is helpful for practical reasons, they are incredibly limited in that they don’t offer richer search capacities, especially in terms of journals and articles, blogs or other digital resources. Also of importance is the fact that WorldCat’s suggestions do not suggest the relative significance or credibility of each text for the researcher, since the hierarchical display of different texts is based on the quantity of books held in WorldCat libraries, with the top 20 “most widely held works” being the only ones listed on the identity page. Potentially, bibliometric tools can be implemented within RoSE on a broader array of texts than within WorldCat, though this may also pose more problems considering the diversity of different media being cited in RoSE (e-literature, digital installations, blogs, newspaper articles, and government publications come most quickly to mind). But the automation of text-text and author-text relations based on WorldCat can be a fruitful starting point for RoSE.
Regarding visualizations, WorldCat offers several different types: timelines, tag clouds, namely bar scales. These are helpful to visualize standard, static information, like dates, numbers of publications, and “audience level” (it is yet unclear how this is calculated). However, these visualizations are not as complex as to visualize connections between different authors and texts. The tag cloud, in particular, links users to other texts that fall under “Associated Subjects,” but these are not necessarily relevant for specific research purposes. RoSE, as it is currently planned, offers more dynamic and navigable visualizations that allow for more concrete and relevant connections to be made between texts and individuals and between documents. The additional “Context” feature currently being implemented in RoSE potentially offers even more specificity for individual researchers, and applying visualizations to it could also prove fruitful. And the discussed “poetic” visualizations can add a uniquely opaque representation of information and relations that is not offered by WorldCat, which focuses primarily on standard and concrete information to aid in finding specific texts, as opposed to poetic visualizations that can aid in interpretive theorizing and questioning.
Additionally, one thing that WorldCat allows for, which RoSE does not, and which Transliteracies may or may not want to consider for the future, is Identity pages for fictional characters that connect them to the literary works that they appear in, as well as to other characters, and to filmmakers and actors who have adapted or portrayed them in theater and film. This can be of particular use for researchers working on specific figures and their appearances in different primary and secondary texts; this, though, is highly specific, and may not be an interest, especially in relation to RoSE’s more high-level theoretical concerns.
Further Reading:
“What is WorldCat?” OCLC.org, 2009. <http://www.oclc.org/ca/en/worldcat/default.htm>
Hudson, Renee. “Freebase Research Report.” Translisteries Website. <http://transliteracies.english.ucsb.edu/post/research-project/research-clearinghouse-individual/research-reports/freebase>
O’Reilly, Tim. “WorldCat Identities.” O’Reilly Radar. 18 Feb 2007. <http://radar.oreilly.com/2007/02/worldcat-identities.html>
Notes:
[i] Sneary, Alice. “Who’s your favorite WorldCat Identity.” WorldCat Blog. 17 June 2009.
[ii] “Audience Level.” Research Activities.
[iii] “WorldCat Identities API.”