Related Categories: Software/coding innovations, text encoding
Summary:
This report describes the core concepts of XML, as well as how to deploy it and its capabilities. It tries to explain XML from scratch without getting too deep into the details. After an introduction and a first example for a possible XML structure and application, an overview about the components of the mechanisms around XML and their benefits is given. The technical analysis describes what exactly is necessary to work with XML and how. The report contains enough information to get entirely started with XML technology, but as XML is a very broad field, this short essay can not claim any form of completeness, and the interested reader should refer to the given references and various books about XML, XSLT and the other technologies involved.
Description:
eXtensible Markup Language (XML) is a language subset of the Standard Generalized Markup Language (SGML). SGML is a meta language, a language for defining other languages. Compared to SGML, XML is less complicated, more intuitive, and because of this more suitable for broad deployment also in non theoretical fields. Cut short XML uses tagged elements(<tagname>content</tagname>) for marking and hierarchically structuring content of any kind and attributes (<tagname att1="extra_content">...) for i.e. grouping, identifying and retrieving content. Nevertheless, neither the names of elements and attributes nor the use of elements or attributes for storage of content are determined by XML. The user can decide how to use those features according to the needs of the specific application.
Example (example.xml):

The above example is a simple model of a book. One of the main benefits of XML is the readability by humans and computers. To assure both attributes, an XML document has to be well-formed (XML syntax conform). That means that every element that is opened by a start tag (e.g. <chapter>) has to be closed by an end tag (like </chapter> in this case). To maintain a hierarchical structure the tags have to be closed in the reverse order of how they have been opened (e.g. <chapter><sentence>text</sentence></chapter>). Empty elements that need a forward slash to indicate the emptiness (e.g. <tocitem />, which is equivalent to <tocitem></tocitem>)Besides that, names, elements, and attributes may only begin with a letter, underscore or colon. This assures that a parser, a software processor that is supposed to read, navigate and partly interprete the xml file, will not be confused by the structure of the document.
“Well-formedness” is essential for XML documents. There is another criteria, namely Validity that can but doesn’t have to be used. An xml file is valid if it follows certain rules, determined by the user in either a Document Type Definition (DTD) or an XML Schema. These are descriptions of how the document is structured, what elements are used and where. Compared to the well-formedness, the usefulness of validity is not that intuitive, especially because it is not always required. Nevertheless, there are various benefits from evaluating validity. A validator will keep track of elements and attributes in undesired locations and assure that no necessary ones are forgotten. That can be very valuable when the document is “written by hand” or when one is developing software using xml as storage or as an interchange format. Furthermore, giving a parser the chance to validate a document enables it to perform various operations , such as, for example, retrieving a specific element by its id. For a more detailed description on how to deploy Validation please refer to the Technical Analysis.
Another very important concept used in XML is the separation of content and representation. XML usually only describes the semantic of the content and determines nothing about how to render it. When, for example, (X)HTML is rendered by a browser, default values are used to determine how for example a second level headline (<h2>Subtitle</h2>) should be rendered, and these default values are modifiable without modifying the html document. This way the same document can be without modification to the original, displayed in a browser, on a small screen of a cell phone, or, perhaps, read aloud by a speech synthesizer. For determining how the document should be displayed in each particular case, usually either Cascading Style Sheets (CSS) , eXtensible Stylesheet Language (XSL), or a combination of the two are used (see Technical Analysis).
The above mentioned attributes of XML (hierarchical structure, well-formedness, validity verifiable etc.) allow for most programming languages to conveniently access, navigate and manipulate xml documents. The Document Object Model (DOM) and SAX (Simple API for XML) are the main interfaces used for this task. They are described in the Technical Analysis, as well.
In contrast to a binary format, XML has the big advantage of extensibility. That means that requirements showing up during the use of software over time can be met by simply adding elements to the format without running into version incompatibility. Furthermore, because of the standardized syntax, simplicity of markup and—in case of validation—easy to meet file requirements, files can easily be shared between competing software systems, counteracting monopolization. This can not only be used in the form of stored files but also for internal or external communication within or between programs. In the case of sending xml data over network interfaces, for example, even applications written in Java and Flash can easily interchange information.
Research Context:
Meta languages, text processing, file interchange between different programs
Technical Analysis:
Well — formedness:
An xml document is well formed when it is conform to xml syntax. Every element that is opened by a start tag has to be closed by an end tag in reversed order.

Attributes consist of a name — value —pair with syntax name=”value”

Validity:
Document Type Description (DTD) :
Can be included in the same file(only for very small projects) or be placed in a separate file and referenced in the xml document:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE report SYSTEM "example.dtd"> [...]
Example for a simple DTD (example.dtd):

Explanation:
Elements:
After the obligatory first line, the “document element” of the format is defined. In every xml only one document element is allowed, as it encapsulates the rest of the content. In this case it is named “report.” After the name follows a description of the elements that are allowed to be included in this element, which is given in brackets. Here these are “toc” and “chapter,” separated by commas. This syntax indicates that both of them have to be present. If it was separated by “|” instead of commas it would mean toc “or” chapter. The delimiter “+” after chapter indicates that chapter has to occur at least once. In contrast, “toc” has to occur exactly once, as no delimiter is given. Other delimiters are “?” for optional elements (once or not at all) and “*” for elements that can occur in unlimited number, including not at all. The next element line determines that the toc consists of one or more tocitems. These, as we see in the next line, are by definition empty, meaning thy cannot enclose any other elements or text. That does not mean they cannot have attributes, as we will see later. The opposite of the EMPTY keyword would be ANY, implying that any element is allowed to be included in this element. The element “chapter” is defined to consist of sentences. Empty chapters are allowed as well, as the “*” delimiter determines. The next element “sentence” is said to be made of #PCDATA. This means “Parsed Character Data,” which says that any text can be included in this element. This text is nevertheless analyzed by the parser software, which can lead to unwanted effects when using reserved characters like “<” or xml itself that should not be reparsed. To avoid this, the parser has explicitly to be told not to interpret this data. Refer to the literature under “Research for further study” for more specific explanation.
Attributes:
The next definitions determine the attributes elements can have. The order of the lines is meaningless; the attribute lists can also be positioned for example directly below the particular element definition. The first ATTLIST definition defines the attribute named “chapter” for the element “tocitem”. The keyword “IDREF” marks this attribute as a reference to a unique identifier of another element. As you see in the example, it refers to “c1” or “c2,” which are the “id” attributes of chapter elements. These attributes are marked in the next definition with the keyword “ID”. This means that these are unique identifiers, and that the parser will produce an error message in case this is not maintained. The keyword CDATA after the attribute name “title” indicates that this is just any text (“character data”) with no further meaning. At this position can also be a list of alternatives, such as (Chapter1 | Chapter2 | Chapter3 ), (yellow | red ) or maybe ( true | false ). Following this data type definition is a keyword indicating if this attribute is necessary (#REQUIRED), optional (#IMPLIED) or fixed (#FIXED).
XML Schema:
As DTDs have various drawbacks —it is, for example, a simple type of system offering very few options (only text types, no numbers, boolean values etc.), an extra syntax without being an independent standard without xml—another approach for determining rules for xml validation is XML schema. Here the document that defines the xml format is encoded in xml itself. It allows for more complex definitions than DTDs and provides more sophisticated mechanisms of various kinds. The drawback here is the complexity of this language compared to DTDs (several hundred pages specifications), making it harder to adopt. Nevertheless if the user has some experience with XML, it is worth the effort.
A schema is referenced in the xml file as an attribute:
<?xml version="1.0" encoding="UTF-8"?>
<report xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="example.xsd">
The following example is the equivalent to the above shown DTD in XML schema (example.xsd):

XML Rendering using stylesheets:
For browsers it can be sufficient to use Cascading Style Sheets to determine how the content should be displayed.
Example (example.css):
sentence { font-family:Helvetica; font-size:12px; font-weight:bold }
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/css" href="example.css"?>
Without this reference the xml file would be displayed by the browser in its default way as xml text with tags, attributes, highlighting and collapsible branches. With the reference, the browser displays only the content of the sentence elements in Helvetica 12px font size, bold.
XSL offers more possibilities to influence the rendering of the content. Additionally, XSL (or, to be more precise, XSLT) can transform a XML document into another XML document (e.g. XHTML or SVG) or something completely different like PDF and therefore use the rendering capabilities of the particular format. Repetition, omittance or restructuring is also possible–as is the combination of more than one xml document.
Similar to the previous examples, an XSL file is referenced in the XML file that should be transformed.
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="example.xsl" ?>
An XSLT processor retrieves this information and uses the style sheet to manipulate the XML file.
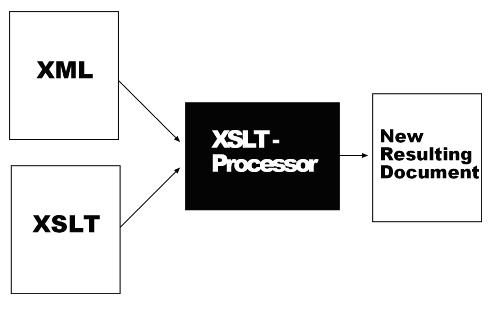
Programming for XML:
All major programming languages offer interfaces for convenient XML parsing, navigation and manipulation. The following two major concepts are particularly well-established:
Document Object Model (DOM)
Using the DOM the whole XML tree is loaded into the memory, enabling programs to navigate anywhere anytime. This is very useful as long as the file does not get too big. The following commands and attributes exist in Java, JavaScript, C++ and others for navigation:
Commands /Attributes and Description:
getElementbyId() gives back a node with a given unique id (validation necessary)
parentNode,childNodes, firstChild
lastChild, previousSibling, nextSibling returns the last element in the list of successors, the previous or next element with the same parent
Those commands are examples for manipulation using DOM:
insertBefore(), replaceChild(), removeChild(), appendChild()
SAX (Simple API for XML)
In this case the tree is traversed sequentially, generating various events, the user can react to.
Examples for these events are:
- startDocument
- endDocument
- startElement
- endElement
- characters
This concept is useful if the particular xml file is very big, as only a small portion of the file has to reside in the machine’s memory.
Evaluation of Opportunities and Limitations for Transliteracies Project:
XML is an extremely important technology, not only but especially regarding text. It can serve as the bridge between text and every other medium and also as a connection between humans and computers, as well as between different computers for text exchange. In terms of the Transliteracies Project, XML could provide a useful tool, in that it might offer ways for us to structure, process, and link text in order to improve online reading.
Research for Further Study:
XML and XML defined languages:
- XML
- XHTML (XML conform HTML) <
- SVG
Example:
<svg width="4in" height="3in">
<g>
<rect x="50", y="80", width="200", height="100" style="fill: #FFFFCC"/>
</g>
</svg>
- MathML
Example:
<mfenced> <mrow> <mi>a</mi> <mo>+</mo> <mi>b</mi> </mrow>
</mfenced>
<msup>
<mn>2</mn>
</msup>
- Resource Description Framework (RDF)
Example:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.0/"> <rdf:Description rdf:about="http://localhost/doc" dc:creator="Fritz Fisch" dc:title="Fishing today" dc:description="A documentary about modern fishing methods" dc:date="2001-03-30" />
</rdf:RDF>
- SMIL
- WML
- X3D