Related Categories: New reading interfaces; New approaches to reading print; Text visualization
Summary:
TextArc is a program designed to display patterns in textual data in a visually accessible format. The program displays each word in a text twice: once in a spiral that contains all the lines, as they appear, in the text and once in larger font to represent its average position within the text.
TextArc promises to convert large texts into a format that allows users to discern patterns in the text. These patterns, however, are based purely on word frequency and, to that extent, limited in what they can reveal about the text.
The designer of TextArc has been invited to use TextArc in several museum exhibitions, including the online gallery of the Whitney Museum of American Art.
Description:
TextArc is a program developed by W. Bradford Paley, an artist and adjunct professor, and released on the web in April of 2002. TextArc creates a visual representation of a text, using the word as its unit of representation.
TextArc uses the words within a text in two ways–as objects placed on the page and as individual units–rendering every occasion of a word twice in the visual product. First, every line in the text is printed, in very small type, exactly as it appears in the text. This takes account of any intentional line spacing by the text’s author, allowing line formatting in poetry, for example, to be reproduced and identified in the visual representation. It also documents the location of a word in a line and its relation to other proximate lines of text. These lines of text are printed to create a spiral (see figure below).
The second time, the word is written in readable type. This printing of the word is related to where it appears in the spiral. Word placement is established based on a word’s average position in the spiral: words used throughout a text will be placed near the center of the spiral while words used only in selective sections will be found close to that portion of the spiral and perhaps even layered over the spiral. Words are “brighter” the more frequently they are found in the text. TextArc also associates a sound with the second printing of a word to represent the word’s frequency. The higher the pitch, the more frequent the word in the text. Because all TextArcs are created in the same fashion, they look similar to one another, even though they are often based on very different texts.
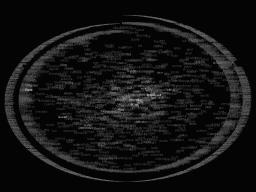
The TextArc representation is interactive. When the cursor is rolled over a particular word, lines appear connecting the readable word to all the places it appears in the spiral (see figure below).

The user can also choose to see the occasions of a word traced linearly through the text, rendered in a curving line through the spiral (see figure below). Additionally, by clicking on any word, TextArc will display a box with every full line of text in which the word appears.
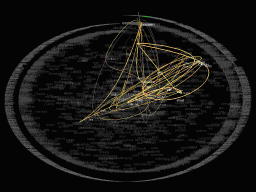
TextArc allows the user to select multiple words and display their connections to the spiral and/or the full lines in which they appear.
TextArc can look for repeated use of word pairs and highlight them in the representation. It also has the capacity to employ word stemming in which it groups words that have a common stem word (e.g., laugh, laughter, laughing, etc.). In grouping these words, it highlights their connection within the visual representation, but it does not modify the representation itself.
Research Context:
TextArc is an interesting foray into the project of distilling meaning from large texts. By considering the placement of a word in a line, related to other lines, TextArc captures the location of words, not just their frequency. Even with this awareness of textual location, however, TextArc importantly divorces words from their linear context by printing the word a second time based on the location of the word in the constructed spiral.
Further, TextArc is established in the art world, having been used in online installations for well-known museums such as the Whitney Museum of American Art. It represents a space where scholars of meaning and artists overlap.
Technical Analysis:
TextArc is a Java-based applet.
Evaluation of Opportunities/Limitations for the Transliteracies Topic:
TextArc does two things of importance to the Transliteracies Project. First, it straddles the line between art and data, suggesting how we can begin to think of online productions as both visually interesting and rich data sources. TextArc’s combination of visual, textual, and aural output from a strictly textual input offers the opportunity to think about how different formats draw on each other and positively reinforce other readings. TextArc represents an important step toward thinking of meaning as more than the formal definitions of words, but also as something that can be seen and heard. TextArc demands new visual strategies to analyze data from the visual representations of texts. One important contribution of this program is how it points to the importance of thinking of the relation between the visual structure of text and textual meaning.
Second, TextArc is highly interactive. TextArc displays data differently based on the user’s approach, in an accessible way. It has a static quantity of data–it is not updating regularly and adding new content–but its interface allows for several renderings of that data.
TextArc’s contribution as a means to measure meaning, however, is relatively small. Although the representations do indeed provide a novel and interesting approach to the texts, the claim that they offer insight into the text is tenuous. Clearly, this rendering of texts offers the opportunity to think of texts in new ways–a particular strength is its ability to depict a lengthy text as a single image–but the assertion that it somehow exposes meaning is naïve.
Further, while Paley describes TextArc as a means to distill meaning from large textual documents, the program uses a fairly simplified concept of meaning. TextArc depends on a definition of meaning that is premised on words themselves. Although TextArc has the capacity to identify word stems and word pairs, the visual representation only allows these groupings to be highlighted; word pairs or word stems do not drive the visual representation.
Finally, this software depends on the assumption that frequency is equivalent to importance. Often, however, it is what’s missing from the text or the way a brief reference to a person or event pervades the text that is most interesting. For example, the gender of the protagonist in Jeanette Winterson’s Written on the Body is ambiguous but of central interest in the novel. Likewise, TextArc does not consider the context of words and thus is ineffective in capturing context-based meaning. Thus, it would not be useful for analyzing large quantities of text in, for instance, the prosecution in The Hague of Slobodan Milosevic, the former Serbian president, in which prosecutors struggled to build a case out of reams of correspondence that lacked a so-called smoking gun.
Resources for Further Study:
Points for Expansion:
Other programs that render visual representations of texts:
- Valence: software that produces visual constructions of large quantities of (usually textual) information.
- Txtkit: text mining software for multilingual texts to render visual representations of large textual sources.